Se le conoce informalmente como Internet Profunda o Internet Invisible (en inglés: Deepweb, Invisible Web, Deep Web, Dark Web o Hidden Web) a una porción presumiblemente muy grande de la Internet que es difícil de rastrear o ha sido hecha casi imposible de rastrear y deliberadamente, como lo es el caso del Proyecto Tor, caso en el cuál ha sido hecha de ésta manera vía usando métodos poco convencionales, cómo con la proxyficación con muchos proxys, el no utilizar direcciones de Internet, sino códigos y el utilizar el pseudodominio de nivel superior .onion, la cuál fue creada por la Armada de los Estados Unidos como una prueba y ahora es aprovechada por delincuentes cibernéticos.

Se le conoce así a todo el contenido de Internet que no forma parte del Internet superficial, es decir, de las páginas indexadas por las redes de los motores de búsqueda de la red. Esto se debe a las limitaciones que tienen las redes para acceder a todos los sitios web por distintos motivos. La mayor parte de la información encontrada en la Internet Profunda está enterrada en sitios generados dinámicamente y para los motores de búsqueda tradicionales es difícil hallarla. Fiscales y Agencias Gubernamentales han calificado a la Internet Profunda como un refugio para la delincuencia debido al contenido ilícito que se encuentra en ella.
Origen
La principal causa de la existencia de la Internet profunda es la imposibilidad de los motores de búsqueda (Google, Yahoo, Bing, etc.) de encontrar o indexar gran parte de la información existente en Internet. Si los buscadores tuvieran la capacidad para acceder a toda la información entonces la magnitud de la ¨Internet profunda¨ se reduciría casi en su totalidad. No obstante, aunque los motores de búsqueda pudieran indexar la información de la Internet Profunda esto no significaría que ésta dejará de existir, ya que siempre existirán las páginas privadas. Los motores de búsqueda no pueden acceder a la información de estas páginas y sólo determinados usuarios, aquellos con contraseña o códigos especiales, pueden hacerlo.
Los siguientes son algunos de los motivos por los que los buscadores son incapaces de indexar la Internet profunda:
Páginas y sitios web protegidos con contraseñas o códigos establecidos.
Páginas que el buscador decidió no indexar: esto se da generalmente porque la demanda para el archivo que se decidió no indexar es poca en comparación con los archivos de texto HTML; estos archivos generalmente también son más “difíciles” de indexar y requieren más recursos.3
Sitios, dentro de su código, tiene archivos que le impiden al buscador indexarlo.
Documentos en formatos no indexables.
De acuerdo a la tecnología usada por el sitio, por ejemplo los sitios que usan bases de datos. Para estos casos los buscadores pueden llegar a la interfaz creada para acceder a dichas bases de datos, como por ejemplo, catálogos de librerías o agencias de gobierno.3
Enciclopedias, diccionarios, revistas en las que para acceder a la información hay que interrogar a la base de datos, como por ejemplo la base de datos de la RAE.4
Sitios que tienen una mezcla de media o archivos que no son fáciles de clasificar como visible o invisible (Web opaca).
La información es efímera o no suficientemente valiosa para indexar. Es posible indexar está información pero como cambia con mucha frecuencia y su valor es de tiempo limitado no hay motivo para indexarla.3 }
Páginas que contienen mayormente imágenes, audio o video con poco o nada de texto.
Los archivos en formatos PostScript, Flash, Shockwave, ejecutables (.exe), archivos comprimidos (.zip,.tar, etc)
Información creada en páginas dinámicas después de llenar un formulario, la información detrás de los formularios es invisible.
Documentos dinámicos, son creados por un script que selecciona datos de diversas opciones para generar una página personalizada. Este tipo de documentos, aunque sí se pueden indexar, no están en los motores de búsqueda porque en ocasiones puede haber varias páginas iguales, pero con pequeños cambios, y las arañas web quedan atrapadas en ellos.3
Es un sitio aislado, es decir, no hay ligas que lo vinculen con otros sitios y viceversa.5
Son subdirectorios o bases de datos restringidas.
Tamaño
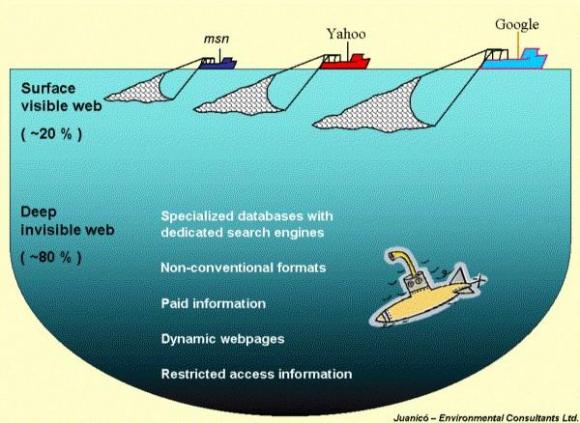
La internet profunda es un conjunto de sitios web y bases de datos que buscadores comunes no pueden encontrar ya que no están indexadas. El contenido que puede ser hallado dentro de la Internet profunda es muy amplio.6
Se estima que la Internet Profunda es 500 veces mayor7 que la Internet Superficial, siendo el 95% de esta información públicamente accesible.
El internet se ve dividido en dos ramas, La internet profunda y la superficial. El Internet superficial se compone de páginas estáticas o fijas, mientras que Web profunda está compuesta de páginas dinámicas. La páginas estáticas no dependen de una base de datos para desplegar su contenido sino que residen en un servidor en espera de ser recuperadas, y son básicamente archivos HTML cuyo contenido nunca cambia. Todos los cambios se realizan directamente en el código y la nueva versión de la página se carga en el servidor. Estas páginas son menos flexibles que las páginas dinámicas. Las páginas dinámicas se crean como resultado de una búsqueda de base de datos. El contenido se coloca en una base de datos y se proporciona sólo cuando lo solicite el usuario.8
En 2010 se estimó que la información que se encuentra en la Internet profunda es de 7,500 terabytes, lo que equivale a aproximadamente 550 billones de documentos individuales. El contenido de la internet profunda es de 400 a 550 veces mayor de lo que se puede encontrar en la Internet superficial. En comparación, se estima que la Internet superficial contiene solo 19 terabytes de contenido y un billón de documentos individuales.
También en 2010 se estimó que existían más de 200,000 sitios en la internet profunda.9
Estimaciones basadas en la extrapolación de un estudio de la Universidad de California en Berkeley especula que actualmente la Internet profunda debe tener unos 91 000 Terabytes.10
La ACM por sus siglas en inglés (Association for Computing Machinery) publicó en 2007 que Google y Yahoo indexaban el 32 % de los objetos de la internet profunda, y MSN tenía la cobertura más pequeña con el 11 %. Sin embargo, la cobertura de lo tres motores era de 37 %, lo que indicaba que estaban indexando casi los mismos objetos.11
Se prevé que alrededor del 95% del internet es internet profunda, también le llaman invisible u oculta, la información que alberga no siempre está disponible para su uso. Por ello se han desarrollado herramientas como buscadores especializados para acceder a ella.5
Denominación
Son páginas de texto, archivos, o en ocasiones información a la cual se puede acceder por medio de la World Wide Web que los buscadores de uso general no pueden, debido a limitaciones o deliberadamente, agregar a sus índices de páginas webs.
La Web profunda se refiere a la colección de sitios o bases de datos que un buscador común, como Google, no puede o quiere indexar. Es un lugar específico del Internet que se distingue por el anonimato. Nada que se haga en esta zona puede ser asociado con la identidad de uno, a menos que uno lo deseé.12
Bergman, en un artículo semanal sobre la Web profunda publicado en el Journal of Electronic Publishing, mencionó que Jill Ellsworth utilizó el término ¨la Web invisible¨ en 1994 para referirse a los sitios web que no están registrados por algún motor de búsqueda.13
Bergman citó un artículo de 1996 de Frank García:14
Sería un sitio que, posiblemente esté diseñado razonablemente, pero no se molestaron en registrarlo en alguno de los motores de búsqueda. ¡Por lo tanto, nadie puede encontrarlos! Estás oculto. Yo llamo a esto la Web invisible.
Otro uso temprano del término Web Invisible o web profunda fue por Bruce Monte y Mateo B. Koll de Personal Library Software, en una descripción de la herramienta @ 1 de web profunda, en un comunicado de prensa de diciembre de 1996.15
La importancia potencial de las bases de datos de búsqueda también se reflejó en el primer sitio de búsqueda dedicado a ellos, el motor AT1 que se anunció con bombos y platillos a principios de 1997. Sin embargo, PLS, propietario de AT1, fue adquirida por AOL en 1998, y poco después el servicio AT1 fue abandonado.13
El primer uso del término específico de web profunda, ahora generalmente aceptada, ocurrió en el estudio de Bergman de 2001 mencionado anteriormente.
Por otra parte, el término web invisible se dice que es inexacto porque:
Muchos usuarios asumen que la única forma de acceder a la web es consultando un buscador.
Alguna información puede ser encontrada más fácilmente que otra, pero ésto no quiere decir que esté invisible.
La web contiene información de diversos tipos que es almacenada y recuperada en diferentes formas.
El contenido indexado por los buscadores de la web es almacenado también en bases de datos y disponible solamente a través de las interrogaciones del usuario, por tanto no es correcto decir que la información almacenada en bases de datos es invisible.16
Rastreando la Internet profunda
Los motores de búsqueda comerciales han comenzado a explorar métodos alternativos para rastrear la Web profunda. El Protocolo del sitio (primero desarrollado e introducido por Google en 2005) y OAI son mecanismos que permiten a los motores de búsqueda y otras partes interesadas descubrir recursos de la Internet Profunda en los servidores web en particular. Ambos mecanismos permiten que los servidores web anuncien las direcciones URL que se puede acceder a ellos, lo que permite la detección automática de los recursos que no están directamente vinculados a la Web de la superficie.El sistema de búsqueda de la Web profunda de Google pre-calcula las entregas de cada formulario HTML y agrega a las páginas HTML resultantes en el índice del motor de búsqueda de Google. Los resultados surgidos arrojaron mil consultas por segundo al contenido de la Web profunda.17 Este sistema se realiza utilizando tres algoritmos claves:
La selección de valores de entrada, para que las entradas de búsqueda de texto acepten palabras clave.
La identificación de los insumos que aceptan sólo valores específicos (por ejemplo, fecha).
La selección de un pequeño número de combinaciones de entrada que generan URLs adecuadas para su inclusión en el índice de búsqueda Web.
Métodos de profundización
Las arañas (Web crawler)
Cuando se ingresa a un buscador y se realiza una consulta, el buscador no recorre la totalidad de Internet en busca de las posibles respuestas, si no que busca en su propia base de datos, que ha sido generada e indizada previamente. Se utiliza el término ¨Araña web¨ (en inglés Web crawler) o robots (por software, comúnmente llamados ¨bots¨) inteligentes que van haciendo búsquedas por enlaces de hipertexto de página en página, registrando la información ahí disponible.18
El contenido que existe dentro de la Internet profunda es en muy raras ocasiones mostrado como resultado en los motores de búsqueda, ya que las “arañas” no rastrean bases de datos ni los extraen. Las arañas no pueden tener acceso a páginas protegidas con contraseñas, algunos desarrolladores que no desean que sus páginas sean encontradas insertan etiquetas especiales en el código para evitar que sea indexada. Las “arañas” son incapaces de mostrar páginas que no estén creadas en lenguaje HTML, ni tampoco puede leer enlaces que incluyen un signo de interrogación. Pero ahora sitios web no creados con HTML o con signos de interrogación están siendo indexados por algunos motores de búsqueda. Sin embargo, se calcula que aún con estos buscadores más avanzados sólo se logra alcanzar el 16% de la información disponible en la Internet profunda. Existen diferente técnicas de búsqueda para extraer contenido de la internet profunda como librerías de bases de datos o simplemente conocer el URL al que quieres acceder y escribirlo manualmente.
Consejos
Lo que te puedes encontrar en la DeepWeb puede hacer que te olvides de lo que ibas a hacer, e incluso que no vuelvas a entrar por lo que hayas podido ver. Si es por curiosidad recuerda el dicho, “La curiosidad mató al gato” y aunque esto no sea muy aplicable a las tecnologías, la DeepWeb puede ser una excepción.
Céntrate en lo que buscas y lo que vas a hacer.
No te fies de ninguna web o vendedor. La confianza en ellos se basa en las experiencias de otros usuarios (lo que tampoco es perfecto).
No hay normas explícitamente dichas. No hay empresas que te ofrecen sus servicios o productos y puedas reclamar o denunciar legalmente.
Desconfía y desconfía hasta que “algo” te demuestre lo contrario.
Busca opciones alternativas, no te centres en la primera.
Estudia cómo funciona la tienda en la que vas a comprar (diferentes métodos de pago y seguridad).
Si temes a la NSA, en la DeepWeb te encontrarás con un panal de abejas y la NSA sólo es una de ellas. Por esa razón, comunícate lo más mínimo y esencial si no has tenido precaución al valorar la seguridad de tus datos.
Dependiendo de lo que vayas a comprar, cuidado con tus datos personales (nombre, dirección, cartera de bitcoins, etc.)
Siempre que puedas o sea necesario, usa PGP Keys para tus comunicaciones o datos.
Tiendas
Hay una larga lista de tiendas en la DeepWeb. Podemos diferenciar aquellas que para entrar es necesario una invitación o referido, las que funcionan en base a la confianza depositada en ellas (casos de estafa, robo de datos, etc. prácticamente nulo) o con sistemas Multisig, las que funcionan con un sistema Escrow (depósito) y por último, aquellos vendedores que han decidido crear su propia tienda con su producto o servicio.
Únicamente listaré aquellas que funcionan con el sistema Escrow, dada su alta seguridad y garantía. Eso no quiere decir que sean imbatibles. Vigilad a vuestros vendedores para evitar el Scam (fraude).

 Por el_facha
Por el_facha